Building an enterprise web app with NodeJS, Firestore, Algolia Search, React, and Cloud Run
Larry’s Problem
After searching for Google Cloud Certified professionals, Larry connected with Deep Auras and described the tech stack of his company, Liberteks, an IT services provider. Liberteks has a dedicated instance of 3CX that enables customers and the general public to call the organization. Each call with customer service agents and technicians is recorded as .wav files on the 3CX server. Then the .wav files are archived to a Google Storage bucket for long term storage. Additionally, the .wav files are transcribed using Google’s Speech-to-Text API and saved to 3CX’s database.
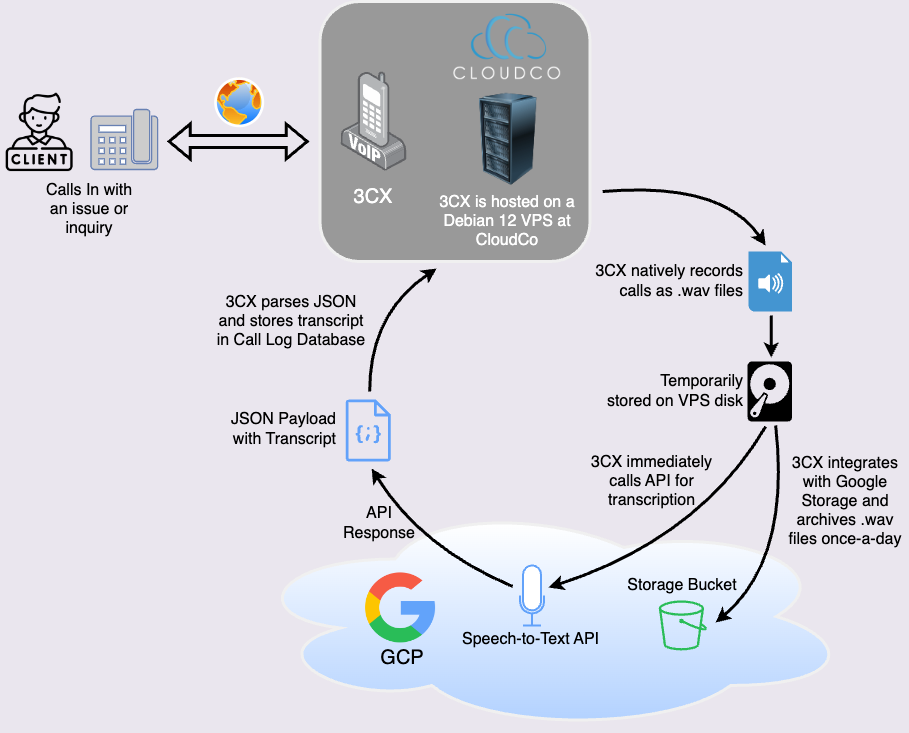
How 3CX Connects with Google Cloud
3CX’s native integration with Google Cloud provided Larry with the ability to store Liberteks’ call recordings (and voicemails) in an affordable and flexible way. However, these recordings are only accessible in 3CX by managers, owners, and system owners. Larry needed customer service agents, technicians, and marketing consultants to be able to review call recordings as well. Additionally, Larry wanted the ability to datamine directly from the Google Storage Bucket without granting more access.
3CX & Google Cloud
Larry’s problem provided Deep Auras with the opportunity to examine 3CX’s native integration with Google Cloud and elevate this connection with more use cases. Uses that generate revenue, cut costs, and enable Liberteks to deliver the next tier of customer service. Let’s take a few moments to review 3CX and why this connection to Google Cloud is important.
3CX is a cross-platform enterprise telephony system
3CX is a software-based unified communications platform that eliminates traditional PBX hardware while delivering enterprise-grade VoIP, video, chat, and SMS through a single interface. Sales teams, call centers, and small businesses use 3CX to ensure their calls are being answered and communication flows clearly. 3CX features the ability to use a Google Cloud Storage bucket to store call recordings, voicemails, and system backups. This takes advantage of Google’s extremely cheap storage and usage costs making it practical for even high-volume recording environments. Administrators can configure the buckets to be multi-regional and redundant, ensuring low-latency performance and compliant data retention.

3CX without Storage Configured Correctly
Get help with 3CX hosting, configurations, and much more
Our Solution
Providing Liberteks with a tool that searches, plays, and downloads call recordings from a Google Storage bucket is a straightforward objective. We began by spending time in Larry’s and the employee’s shoes to gain a better understanding of how features would be actually used. Additionally, we evaluated the “Recordings” panel in the 3CX’s admin menu to be a starting point as well.
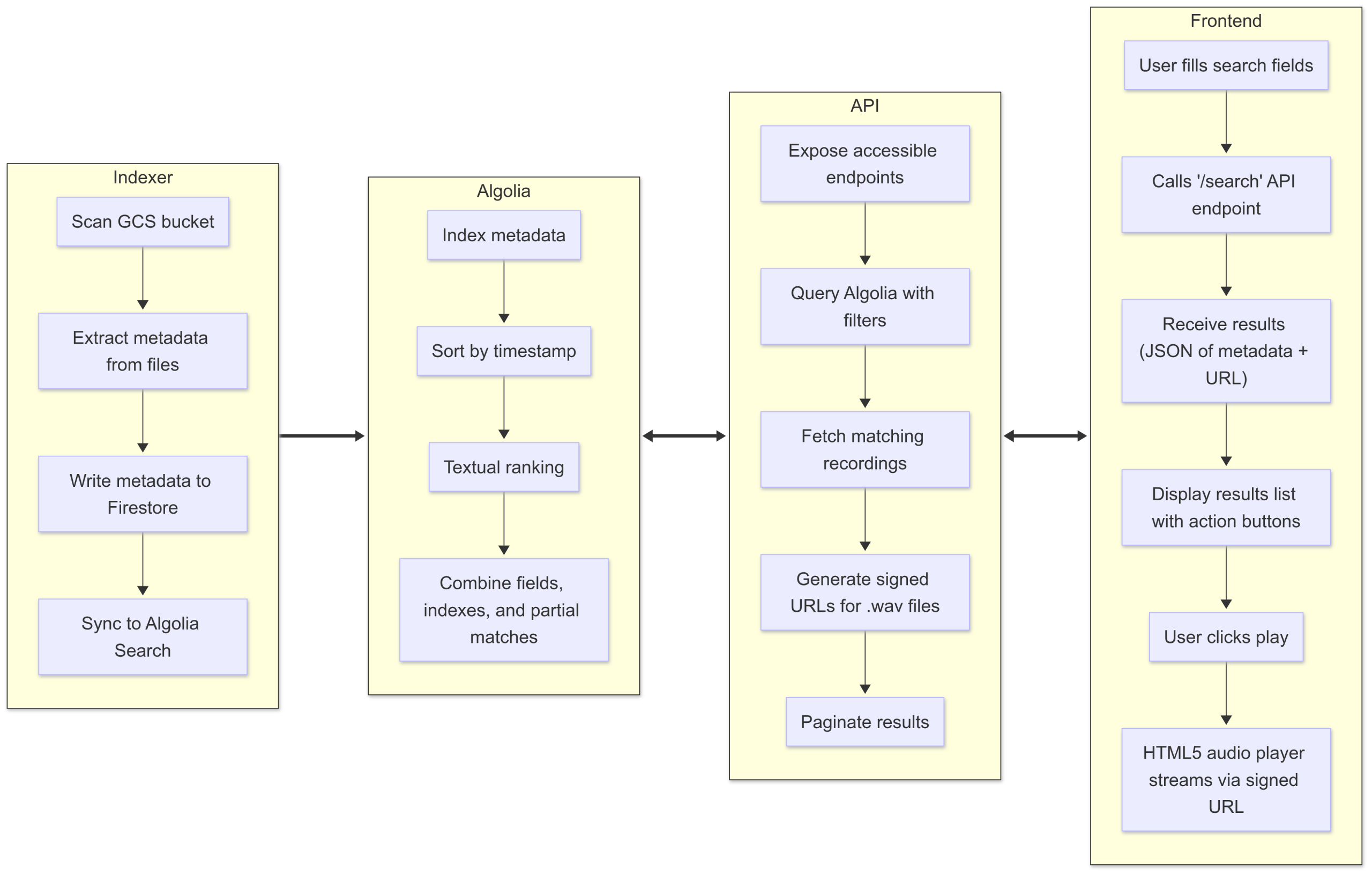
Our solution charted out
Our design plan to meet Liberteks’ needs comprised of 4 main components:
- High-performance, asynchronous NodeJS file indexer.
An efficient indexer that extracts the metadata of each file in the Google Bucket and populates a Firestore database. - First-class search UX by leveraging Algolia.
Algolia’s indexing, fast-faceting, and partial matching empower users beyond simply translating field inputs into Firestore queries. - REST API to seamlessly manage data interchange.
An extensible backend that provides the routing for user input, integrations, and generates signed URLs securely. - Responsive, mobile-friendly React frontend.
A simple, stylish single-page application that users interact with to search, play, and download recordings as well as voicemails.
Each of the components would be deployed on Google Cloud’s serverless option: Cloud Run. This enabled Deep Auras to set up Continuous Development / Continuous Integration with Google Cloud Build and offer Liberteks a cheap way to maintain the infrastructure. Once Deep Auras had access to Liberteks’ Google Cloud project, it was a smooth process to provision all the cloud resources and we began development.
High-Performance NodeJS Indexer
3CX stores the call recording metadata in 2 places: its own internal database, accessible via API calls (or by using ‘Data Connectors’, a new feature unavailable at the time of development) and directly in the filename string. We could either parse the string and extract the metadata with regular expressions (regex) or make thousands of API calls to the 3CX instance.

This was an option we considered
We opted to parse the filename string with regex, despite it being a fragile approach. If 3CX changes their naming convention in the future, the current regex would not match. From our research, 3CX has not changed this convention for the last 7 years and ideally will not change it. Thankfully, adding another set of regex cases is trivial if 3CX does make future changes. Our first regex matched most of the call recordings and was based on 3CX support posts:
let match = name.match(/^(.+?)\/(.+?)\/\[(.+?)\]_(.+?)-(.*)_(\d{14})\((.+)\)\.wav$/);
if (match) {
let [_, directory, subdirectory, displayName, extension, phoneNumber, timestamp, callId] = match;
...
}We also wanted to include voicemails that were being archived to the bucket too and that became the second regex:
match = name.match(/^(.+?)\/(.+?)\/(.+?)_(.+?)_(\d+)_(\d{14}).wav$/);
if (match) {
let [_, directory, subdirectory, displayName, phoneNumber, extension, timestamp] = match;
...
}When we reviewed the logs of files that were not matched against the first regex case, we discovered that some .wav files did not have the ‘displayName’ datum. Then we wrote a third regex for this edge case:
match = name.match(/^(.+?)\/(.+?)\/\[]_(.+?)-(.*)_(\d{14})\((.+)\)\.wav$/);
if (match) {
let [_, directory, subdirectory, extension, phoneNumber, timestamp, callId] = match;
...
}With these 3 regular expressions, we achieved 100% coverage on matching filename strings and extracting the metadata from all the files. Additionally, we were able to convert the timestamp from YYYYMMDDHHMMSS to unix format and determine the call direction of the recording.
After regex matching, writing to Firestore/Algolia, and logging, the indexer script was less than 300 lines. Yet, when we tried to index all 17,000+ files (> 100 GB) on Liberterk’s storage bucket, it took around 5 minutes to complete. 5 whole minutes and a little more. The system administrator has to wait 5 minutes…36 times greater than the average attention span of an American. What if they completely forget what they were doing while the indexer is running automatically in the cloud on a cron-job?

One of our project managers
To achieve better performance, we decided to batch the database writes and implement concurrency. While the indexer waits for the database to finish writing, it can move on to the next file for metadata extraction. This enables efficient file processing and reduces the run time to less than a minute. Not bad for a NodeJS script without a server!

NodeJS is a Google javascript runtime used for server-side applications
Supercharge your backend operations and services with Node experts
Algolia Search
Although Firestore is a good database solution native to Google Cloud, it does not support full-text search, partial matches, or combining filters flexibly. Google recommends using a dedicated third-party search service and we chose Algolia. Algolia provides an innovative, performant, and leading-edge data fetching methodology that is honed to user search experiences. It’s strange to pronounce, but easy to use and pipe into future updates like searching through transcriptions.

Algolia can quickly search vast dataspaces
REST API
Developing a robust architecture based on REST principles and best practices is where the magic of our solutions lie. There is a quiet elegance of taking user input data, seamlessly searching thousands of records, and responding to many requests simultaneously. We chose to use to the Express framework to develop this API to do the following:
- Authenticate using Microsoft Entra as Liberteks uses M365 organization-wide.
- Expose a ‘/search’ endpoint for user clients to send input field data.
- Generate signed URLs so that users can stream or download .wav files from the bucket.
Ready to build robust APIs and microservices?
The REST API aptly uses Algolia and Google Cloud Storage packages to interface with those services in an obfuscated and secure manner. This eliminated the need for Larry to grant more access to Liberteks’ Google Cloud console: As long as they had an ‘@liberteks.com’ M365 account, they would now be able to search the bucket and retrieve the files.
React Frontend
We chose React as our frontend framework to develop a lightweight SPA that would function well on mobile devices and take advantage of the wide real-estate of desktop browsers. Our approach is simple:
- Map out the features in 3CX’s ‘Recordings’ section in the Admin Control Panel.
- Consider the current user experience pitfalls of 3CX’s ‘Recordings’ and refine an innovative UI/UX plan based on realistic, contemporary design patterns.
- Execute the UI/UX plan by:
- Draft lo-fi wireframes to determine superstructures and then drill down the design, behavior, and style of the components
- Coding the API and Microsoft Authentication Library (MSAL) services
- Transmute the designs into functional React components
- Implement Tailwind CSS for styling using the Liberteks website as a reference
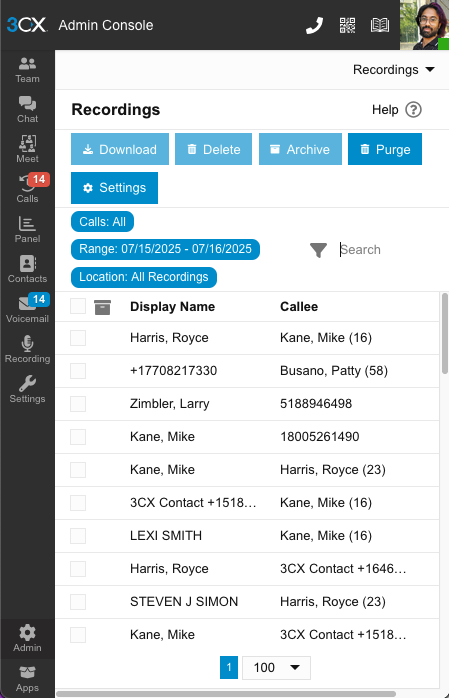
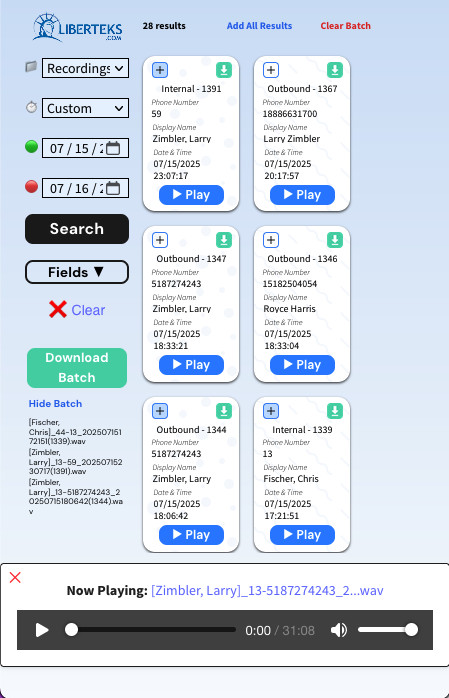
3CX’s UI vs Deep Auras’ UI
The 3CX UI relies on a table of results that are paginated and stack the search fields on top of the results. This ends up crowding the window and reduces the number of results that can be displayed. Additionally, the functionality to stream the file is not available and you have to download the file instead.
Since our app was focused on searching, playing, and downloading recordings, we divided up the page so that the search fields wouldn’t impact the results and to allot space for the audio player. The major weakness of a table is that it relies on width or a lot of horizontal scrolling so the user can read the information. To address this, we designed a card layout for the recordings that neatly encapsulates the information for the user to quickly read. Furthermore, we implemented lazy loading so that users can quickly scroll through results without manually loading the next page. Lastly, we incorporated the ability to group recordings together into a batch download.
When we see the callback pyramid of doom of in the wild
Transform your digital experiences with modern React apps that users love
What’s Next?
After deploying to Google Cloud Run, we completed User Acceptance Testing and QA on the data retrieval and results. Liberteks staff are now able to provide superior customer service and ensure the details of each case does not fall through the cracks. Larry and his team outlined the need to read transcripts along with playing back the files. Fortunately, we will be able to export the transcripts from 3CX into our Firestore database and perform full-text search and heuristics with Algolia. Stay tuned to our future case studies detailing future upgrades to this app and the use of Copilot Studio to build agents that generate revenue driving deliverables.